Raspberry Pi 3 Floating-point Benchmarks
By  on March 31, 2016
on March 31, 2016
Keywords: raspberry pi benchmark threaded ARM
There's been a lot of hype about the Raspberry Pi 3's performance, but how does it fare with signal processing for software-define radios? Here are some benchmarks for multi-threaded performance with liquid-dsp.

The Raspberry Pi 3. Same price, better floating (point) performance.
The Raspberry Pi Foundation released the third version of their popular development board at the end of February this month, and like a good engineer I decided to put it through the SDR wringer . Unlike my previous I did not include the Beagle Bone . Here are what the three incarnations of the Pi look like side-by-side:

Evolution of the Pi: one, two, three.
Notice a trend? That's right; the silkscreened raspberry is getting smaller. Probably to make room for more horsepower and onboard WiFi (see the tiny antenna on the top right corner of the card). While the 3 offers a CPU speed improvement of 1200 MHz over the 900 MHz of the 2, the real performance bump comes from an improved ARM architecture; from the quad-core ARM Cortex-A7 on the 2 to the quad-core ARM Cortex-A53 on the 3.
First impressions∞
As with previous version of the Pi, the 3 includes neither a power supply nor an SD card for hosting the operating system with the ^35 price tag. This is fine as it keeps the cost of the device low and allows customization of the hardware, but it does change the meaning of BYODKM to Bring Your Own Display, Keyboard, Mouse, Power Supply, and Flash Drive. This wouldn't normally be a problem, except that the Raspberry Pi 3 consumes a lot more current than its predecessors under max power load. I hadn't realized this at first and found that any time I tried to do anything with all four cores running full speed the OS would crash. As it turned out the power supply I was using for the Raspbery Pi 3 was only rated to 700 mA, and running all 4 cores at once drew too much current and caused a voltage drop in the CPU. Processors don't tend to like this too much.

Oh, you tricky little devil. So hungry for power are you!
After a bit of rummaging in some old computer storage bins in my closet I was able to find a USB Micro-B supply that went up to 1000 mA which ended up being sufficient for the job. Even still, I ordered a 2400 mA wall adapter for future development just to be safe.
The Benchmarks∞
For the actual benchmarks I just modified the program from my Raspberry Pi 2 benchmarks to allow options for testing different filter lengths and buffer sizes. It basically just creates a set of threads that run independent firfilt_crcf operations as quickly as possible. It's nothing heroic, but it gets the job done. You can download the program here: benchmark_threaded.c . Just first install liquid-dsp and then compile it with:
gcc -Wall -O2 -o benchmark_threaded benchmark_threaded.c -pthread -lm -lc -lliquid
The figure below clearly shows the performance gains between the three devices. Notice that while the CPU speed of the 3 was bumped 33% from 900 MHz to 1200 MHz over the 2, the performance more than doubled. Never underestimate the importance of a good CPU architecture.
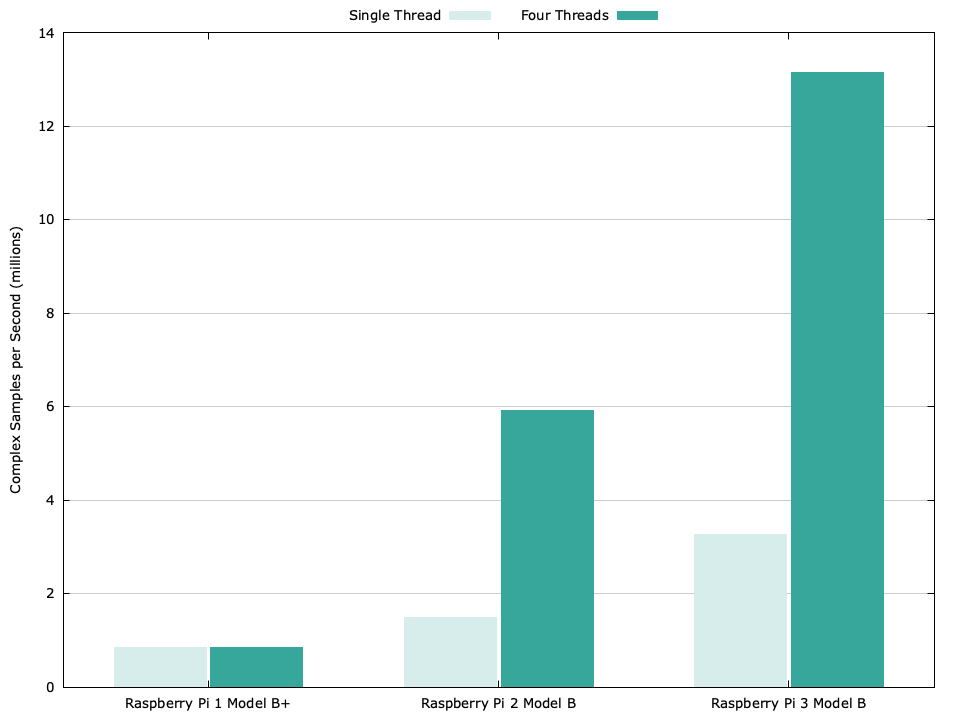
Performance results at a glance. The filter length is 57 coefficients and the buffer size is 256 samples.
I also wanted to see how the performance scaled with certain parameters of the program (number of threads, buffer sizes, and filter length):
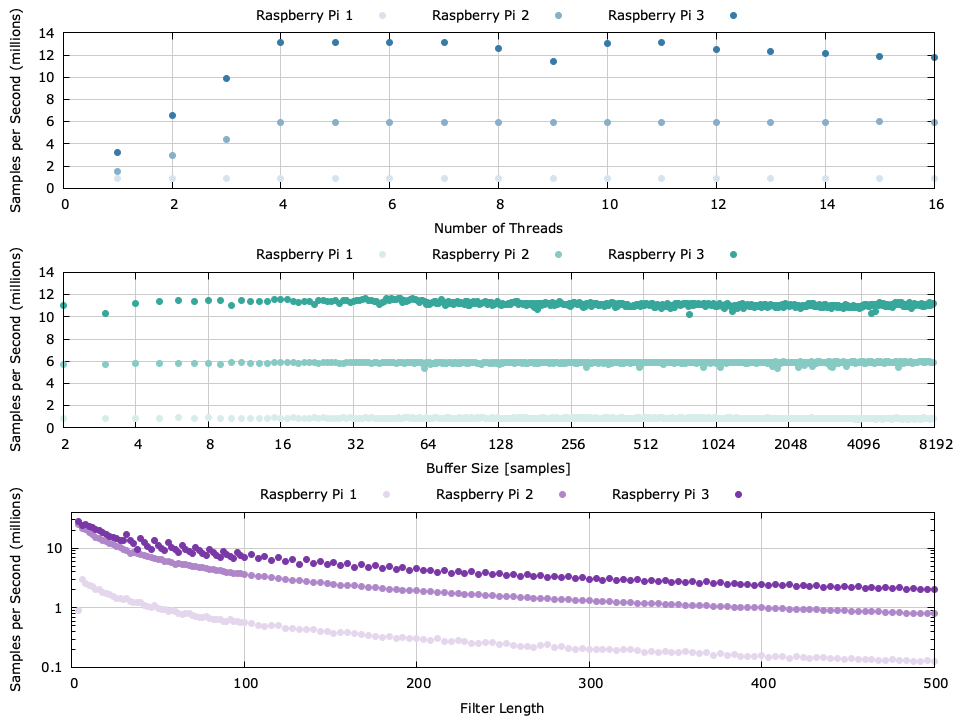
Detailed performance results between the Pis. The default configuration is 4 threads, 57 filter coefficients, and 256 samples in the buffer.
The figure above shows some unsurprising results:
- The computational bandwidth scales linearly with threads up to 4 where it (mostly) tails off; although there is a bit of fluctuation with the 3 for more than 7 threads
- Having an overly large or small buffer doesn't adversely affect performance. This is most likely because I was lazy when I wrote the program and the threads don't synchronize between buffers as they probably should. If this were the case then small buffers would cause a lot of overhead in synchronization, causing performance to suffer.
- The performance has an inverse relationship to filter length. The number of complex operations required for each output is linearly proportional to the filter length. The undulating nature of the performance of the Raspberry Pi 3 under 100 coefficients is because the SIMD extensions liquid-dsp uses for the vector dot product operates in blocks of 16 samples. That is, there is a little overhead for the filter size modulo 16 coefficients. As such, a filter with 64 coefficients runs faster than one with 59.
Conclusion∞
As always it's nice to see performance match expectation, and the Raspbery Pi 3 certainly lives up to its hype. This little guy has some pretty considerable heft for something that costs ^35 and has a massive support community behind it.